目录:
——初步认识浏览器
——浏览器的渲染机制
——浏览器的缓存机制
正文:
初步认识浏览器
想来任何一位读者,对浏览器都不会陌生。除开IT相关人员常用的Chrome(谷歌,Google)、Firefox(火狐,)、IE(微软),大多国内用户可能更熟悉诸如 百度浏览器、360浏览器、QQ浏览器、猎豹浏览器、UC浏览器……
(ps:以上排名不分先后)
OK,请打量您当前使用的浏览器——我们先认识一下浏览器的概念:
浏览器是指能够显示HTML文件内容,并让用户能够与这些文件进行交互的一种软件。
由上述概念可以清楚地认识到三个重点:
一能够显示HTML文件内容
再次请观察您当前所用的浏览器,请注意,你所看到浏览器里的内容——也就是包括这篇博客,它本质上就是一个HTML文件(这里要补充一点:现时代的浏览器,有些也能显示其他格式的文件)。
按下快捷键 F12,在Elements里所呈现的就是一个完整的HTML文件内容,浏览器通过解析它将内容渲染到浏览器界面上,就是读者目前所看到的网页内容。
二让能够与这些文件进行交互
交互直译为交流、互动。比如:点击导航进行页面跳转,在注册表单里填写内容然后提交,点击评论输入你的读后感,F12里对元素属性改写……
无论是PC端,还是移动端,大多数交互,我们称之为事件——在场各位,常用的点击事件(click/touch)、鼠标事件(mouse)、键盘事件(key)、改变文本事件(change)……(此处省略很多很多事件)总而言之,我们与浏览器的交互,大多都被称之为事件(注意,不是事故)。
三一种软件
之前的两点说的是浏览器的功能,这里要重点说明浏览器的构成。
如图:

即:
1用户界面:即读者目前所看到的浏览器界面,除开当前窗口显示的网页,其他的就是用户界面。(注意,不包括显示的网页)
2用户界面后端(UIBackend):功能上讲,能够绘制浏览器独有的弹窗会话、组合框等小窗口部件,对页面开发者来讲,也可以通过js脚本指令让它工作。
3网络:用来执行网络请求。浏览器通过它与网络层沟通,和web服务器建立联系。
4浏览器引擎:可以理解为渲染引擎和用户界面之间的中间层,把一方的指令传给另一方,让另一方对应工作。
5渲染引擎:解析HTML文件中的html标签和css样式规则,并将内容绘在窗口中。
6 Js解释器:解析并执行HTML文件中的JavaScript脚本代码。
7 Persistence(存储)/Storage(仓库):在硬盘上保存数据的本地仓库,是实现浏览器缓存的依赖。——一般来讲默认在浏览器目录里创建文件夹。
以上,是整个浏览器的功能组件构成。
小白可以这样理解:HTML文件内容==html(超文本标签语言)+css(修饰html元素的布局样式规则)+js(脚本指令代码)。
浏览器的渲染机制
了解过浏览器内部的实现结构,那么对于浏览器如何去请求html页面并将其解析,最后渲染到浏览器窗口内的这个过程,你就能通过下面这张图看个明白了。
如图:
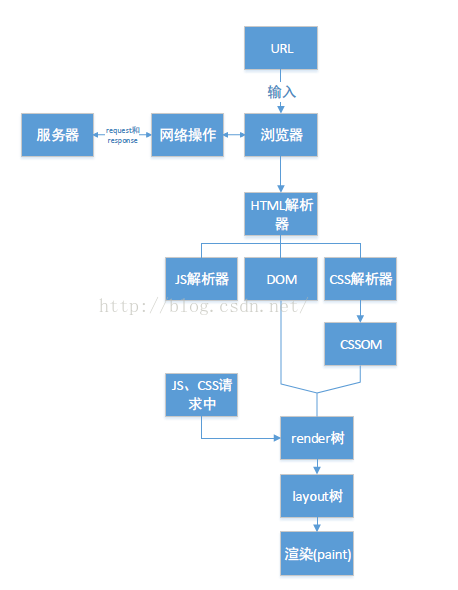
(该图取自csdn 博主的博客,以谷歌浏览器引擎 为基准 )
解读该图:
1、 用户输入一个URl地址请求后,请求成功,得到了返回的HTML。(这里请求发出后的实现过程,请往下看——浏览器缓存机制)
2、 浏览器的HTML解析器会将这个文件解析,并且构建成一棵DOM树。
3、 在构建DOM树的时候,遇到JS和CSS元素,HTML解析器就换将控制权转让给JS解析器或者是CSS解析器。(意思是常规情况下,同一时间只能调用一个解析器)
4、 JS解析器或者是CSS解析器解析完这个元素时候,HTML又继续解析下个元素,直到整棵DOM树构建完成。
5、 DOM树构建完之后,浏览器把DOM树中的一些不可视元素去掉,然后与CSSOM合成一棵render树。
6、 接着浏览器根据这棵render树,计算出各个节点(元素)在屏幕的位置。这个过程叫做layout,输出的是一棵layout树。
7、 最后浏览器根据这棵layout树,将页面渲染到屏幕上去。
浏览器的缓存机制
这里首先提两道面试题:当用户在浏览器地址栏里输入了,按下回车后发生了什么?状态码304是什么意思?
3开头的状态码都是重定向的意思。304意思是请求重定向到本地浏览器缓存。
按下回车后,会先解析这个域名,转化为IP地址,发送请求。
我画了一个简单的请求图:

可以看到,我们的浏览器发送的请求会先在网络层进行一个判断。
如果浏览器本地缓存有效,就不用在请求服务器了~~(这样做的目的是 :节省了请求的时间,缩短了用户等待响应的时间,有效减少服务器被请求的次数。)
如果浏览器本地缓存无效,这个请求就会发送到服务端,服务端收到请求之后,要返回一个结果(响应),这个结果会原路返回到浏览器(返回的时候干了什么?读者不妨自己思考一下)。
——
请求有请求头,那么响应也自然有响应头。
服务端在响应头里设置了哪些东西应该被浏览器缓存,缓存的方式、存储的地点以及缓存的时间。
按照这个逻辑,我们再画一张响应图:
……算了画图太累了。自行脑补,或者查阅相关文章。
这里给一个不错的链接:
(浏览器缓存机制)
Ok,入门篇尽量使小白看得懂,因此太复杂的我们暂且先放一放。
浏览器的存储方式什么的后续篇章再讲。
本文介绍到这里,告一段落。
写在最后
本文属于Web项目的基础篇。
本文参考:
浏览器渲染机制:https://blog.csdn.net/cde7070/article/details/50619853
两张结构图为笔者个人灵魂画作。
本文中如有说法不当之处请留言指出,谢谢。